golang map
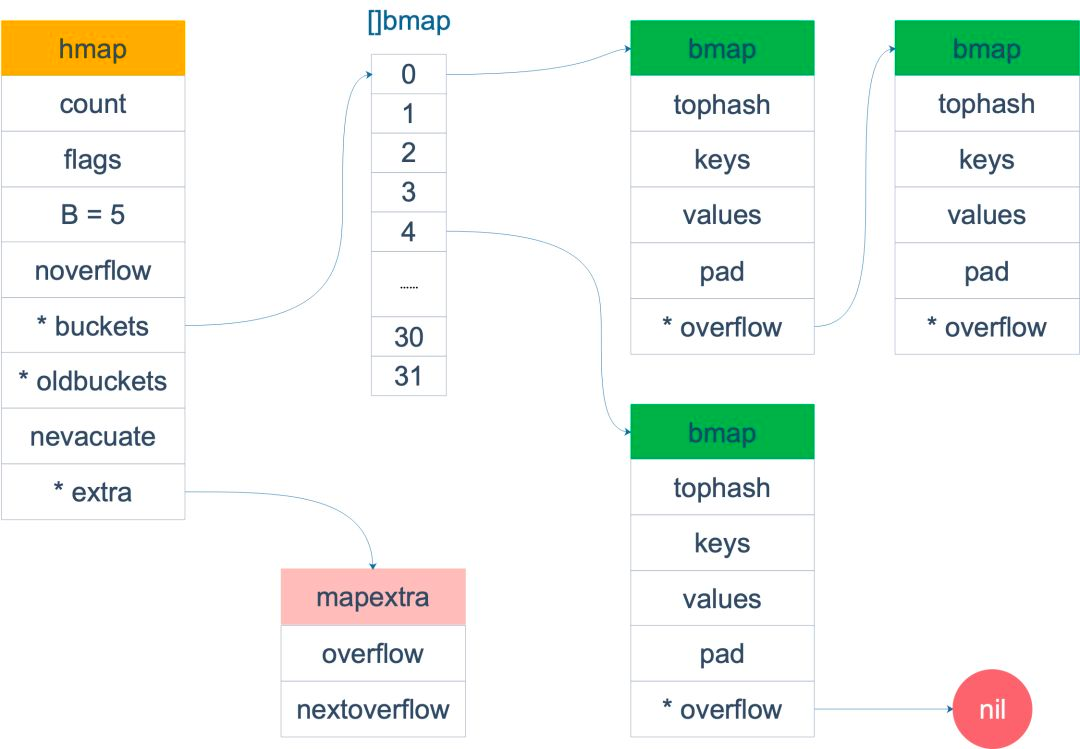
hmap
map 是引用类型,指针指向 hmap 结构体,hmap 的 源码 如下:
type hmap struct {
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
- count 表示map中元素个数
- flags 是一个状态标识,有4个值,分别是
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
- B 表示桶个数的对数
- noverflow 是溢出桶个数的近似值
- buckets 指向 bmap 数组
- oldbuckets 和扩容有关,指向扩容时的旧桶
bmap

hmap 中的 buckets 和 oldbuckets 指向的是 bmap 数组,一个 bmap 可以放 8 个元素,bmap 源码,编译过程会加料,最终 bmap 结构体会是这样的:
type bmap struct {
tophash [8]uint8
keys [8]keytype
values [8]valuetype
pad uintptr
overflow uintptr
}
tophash 存储 hash 值的高8位,需要注意的是,tophash 值小于等于 5 存储的是状态。
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
通过 key 的 hash 值和 B-1 做与运算,判断元素落在哪个桶中,在通过 tophash 确定在桶的位置,然后根据 tophash 判断 bucket 的该位置是否可用,如果 8 个位置都不可用,则会链出一个指针指向一个新的 bmap 作为溢出桶。
当 map 的 key 和 value 都不是指针,并且 size 都小于 128 字节的时候,会把 bmap 标记为不含指针,以避免 GC 扫描整个 hmap。这时候 overflow 指针会被放到 mapextract 中,以保证 bmap 中不包含指针。
loadfactor
golang map 的 loadfactor 为 6.5。
make map
创建 map 会调用 makemap 函数,函数 源码。
创建 map 的流程如下:
- 计算 B
B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
- 如果 B != 0, 则申请桶空间
if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
if nextOverflow != nil {
h.extra = new(mapextra)
h.extra.nextOverflow = nextOverflow
}
}
mapaccess
由于读取 map 的返回值有三种,所以函数有三个,分别对应着返回单个值、返回值和bool,返回key和value。 mapaccess1, mapaccess2, mapaccessK。
读取流程如下:
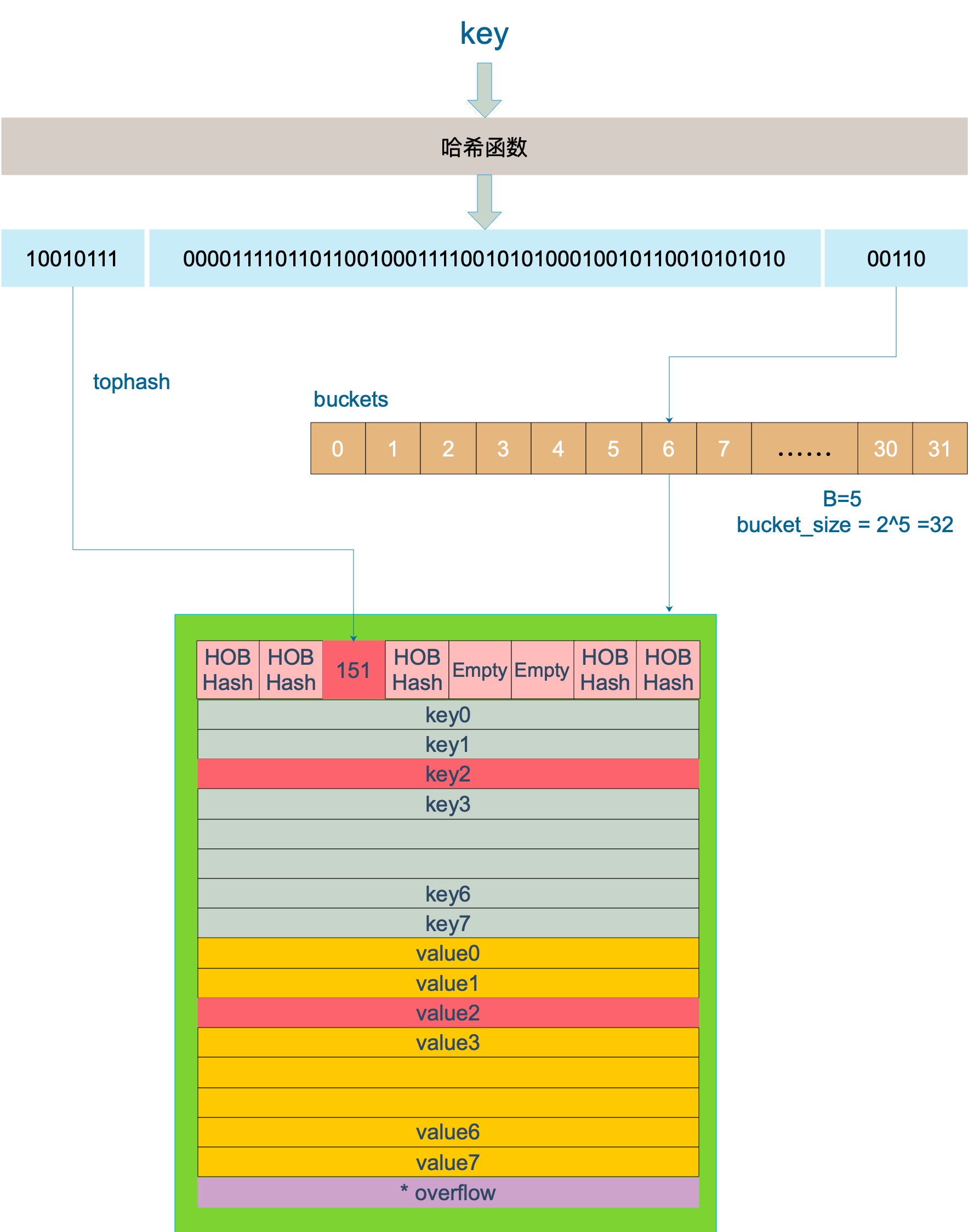
- 计算 key 的 hash
- 用 key 的 hash 的低 B 位定位桶
hash := t.hasher(key, uintptr(h.hash0))
m := bucketMask(h.B)
b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.bucketsize)))
- 判断是否需要从旧桶里找
if c := h.oldbuckets; c != nil {
if !h.sameSizeGrow() {
m >>= 1
}
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.bucketsize)))
if !evacuated(oldb) { // 判断 top hash 是不是 evacuatedX 或 evacuatedY
b = oldb
}
}
- 取 top hash
top := tophash(hash)
- 通过 top hash 和 key 在桶内查找 key
for ; b != nil; b = b.overflow(t) {
for i := uintptr(0); i < bucketCnt; i++ {
if b.tophash[i] != top {
if b.tophash[i] == emptyRest {
break bucketloop
}
continue
}
k := add(unsafe.Pointer(b), dataOffset+i*uintptr(t.keysize))
if t.indirectkey() {
k = *((*unsafe.Pointer)(k))
}
if t.key.equal(key, k) {
e := add(unsafe.Pointer(b), dataOffset+bucketCnt*uintptr(t.keysize)+i*uintptr(t.elemsize))
if t.indirectelem() {
e = *((*unsafe.Pointer)(e))
}
return e
}
}
}
mapassign
写入数据会调用 mapassign 函数,写数据和读数据的流程相似,只不过多了扩容判断。
- 首先判断是否是并发写入, 并设置 flags
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
h.flags ^= hashWriting
- 判断是否需要扩容
bucket := hash & bucketMask(h.B)
if h.growing() {
growWork(t, h, bucket)
}
- 定位桶和计算hash top
b := (*bmap)(add(h.buckets, bucket*uintptr(t.bucketsize)))
top := tophash(hash)
- 遍历桶找到插入的位置
- 如果key 存在,则更新
- 修改flags
h.flags &^= hashWriting
mapdelete
删除操作调用 mapdelete 函数。
- 写保护
if h.flags&hashWriting != 0 {
fatal("concurrent map writes")
}
h.flags ^= hashWriting
- 确定桶的位置
hash := t.hasher(key, uintptr(h.hash0))
bucket := hash & bucketMask(h.B)
- 判断扩容
- 遍历桶寻找key,找到key则删除元素并更新 tophash
if t.indirectelem() {
*(*unsafe.Pointer)(e) = nil
} else if t.elem.ptrdata != 0 {
memclrHasPointers(e, t.elem.size)
} else {
memclrNoHeapPointers(e, t.elem.size)
}
b.tophash[i] = emptyOne
...
- 解除写保护
h.flags &^= hashWriting
扩容
- 如果 loadfactor 超过6.5,触发翻倍扩容
- 如果溢出桶过多则触发等量扩容
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {
if B > 15 {
B = 15
}
return noverflow >= uint16(1)<<(B&15)
}
- 扩容过程为渐进式扩容