golang语言机制之栈与指针
学习和使用 golang,就不得不了解 golang 的指针。如果不能很好的理解指针,很难写出简单、整洁并高效的代码。
帧边界(Frame Boundaries)
帧边界为函数执行提供了独有的内存空间、上下文(context)环境和一些流控制。函数可以通过帧边界指针直接访问帧边界的内存,或者间接访问帧边界外的内存(不能直接访问帧边界外的内存)。函数要间接访问帧边界外的内存,被访问的内存必须和函数共享。我们首先来了解一下帧边界建立的机制和限制。
函数调用时,会在两个相关的帧边界间进行切换,从调用函数切换到被调用函数,如果函数调用时需要传递参数,那么这些参数值也要传递到被调用函数的帧边界中。Go 语言中帧边界间的数据传递是按值(by value)传递的。
按值传递的好处是可读性好,函数调用时传入的值就是函数真正接收到的值。按值传递又叫做 WYSIWYG(what you see is what you get)。在发生切换时,我们可以很清楚的了解函数调用将如何影响程序执行。
程序 1 展示了函数调用按值传递。
// 程序 1
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
// Pass the "value of" the count.
increment(count)
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc int) {
// Increment the "value of" inc.
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
}
程序执行时,运行时(runtime)创建 main goroutine 来初始化代码。goroutine 最终在操作系统线程(os threads)上执行,从 golang 1.8 开始,每个 goroutine 的栈空间是 2048 字节连续的内存空间,栈空间大小未来可能还会变化。
栈空间为每个函数的帧边界提供了物理内存空间,main goroutine 执行程序1中的 main() 方法时栈空间看起来应该是如图1这样的:
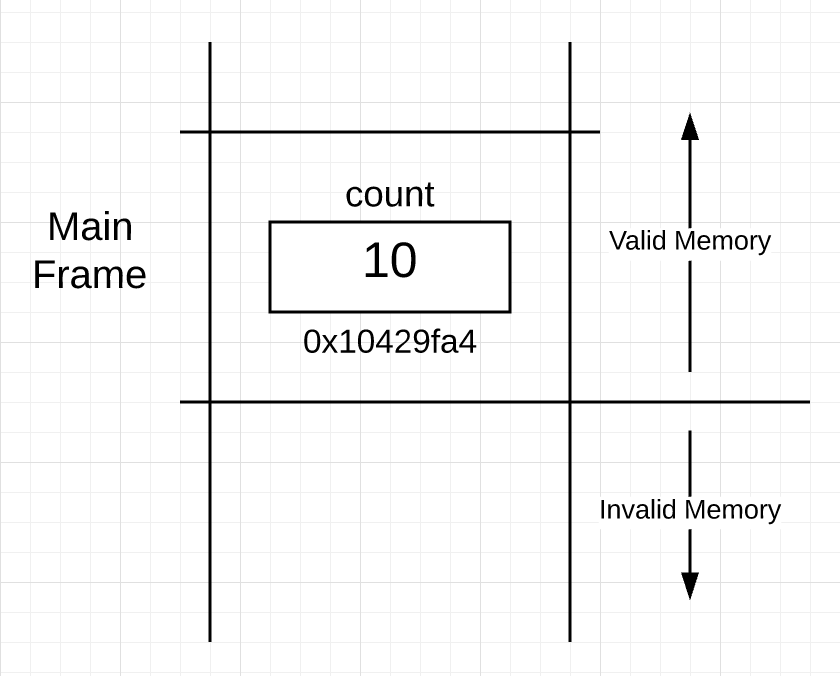 图 1
图 1
如图 1 所示,栈空间已经划出了一块作为 main frame,这块区域叫「栈帧」,界定了 main 函数在栈上的边界。这块栈空间随着代码的执行而被创建,变量 count 在这块栈空间的地址是 0x10429fa4。
图1还展示了一点,在活跃的栈帧外的内存空间是不可用的,可以内存空间和不可用内存空间的边界需要明确一下。
地址
变量名表示一个内存地址,如果存在变量值那么内存中一定存在变量值,变量值一定会有内存地址。程序 1 的第 9 行打印出了 count 变量的值和地址:
println("count:\tValue Of[", count, "]\tAddr Of[", &count, "]")
golang 中使用 & 操作符获取变量的内存地址,这一行代码的输出如下(每次运行变量的地址可能不一样):
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
函数调用
程序 1 的第 12 行调用了 increment 函数。
increment(count)
函数调用意味着需要在栈上开辟新的空间,除此之外,需要将参数跨越帧边界传到新的栈帧中。这里需要将 count 变量传递给increment函数。程序 1 的第 12 行调用 increment 函数传递的是 count 变量的值,会复制 count 变量的值并传递到 increment 函数的栈帧。而 increment 只能修改自己栈帧的 count 变量的副本。调用 increment 方法栈空间如图 2:
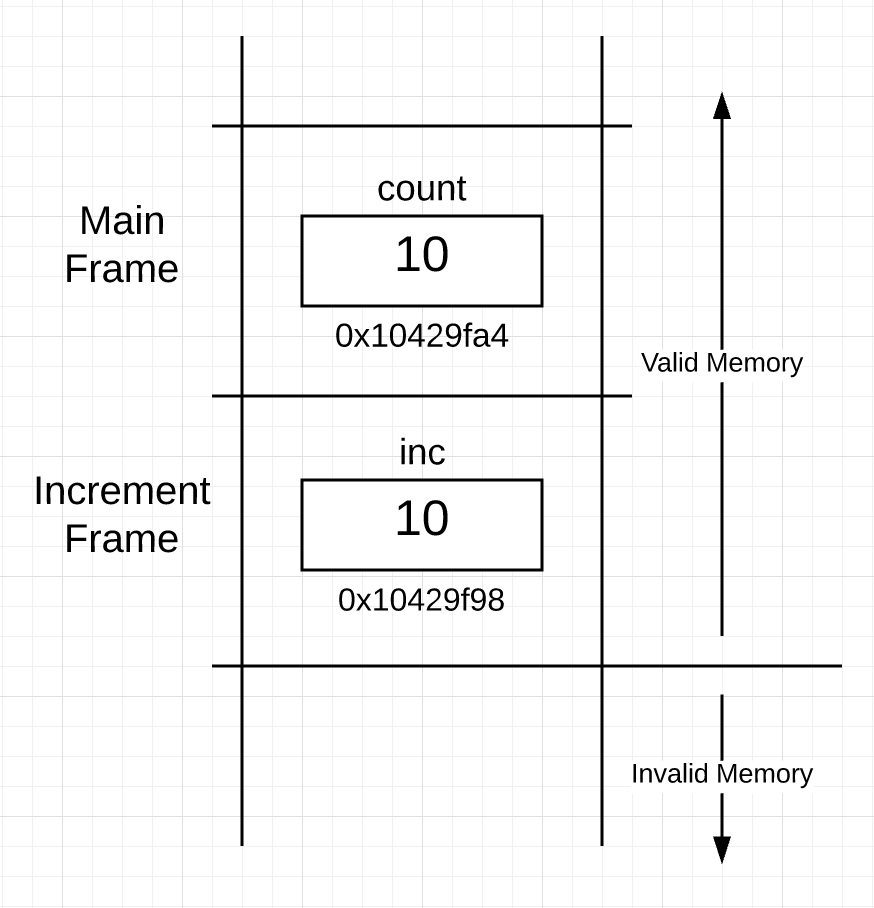 图2
图2
现在栈空间有两个栈帧,main 函数栈帧和 increment 函数栈帧。在 increment 函数栈帧,可以看到 inc 变量,变量值是 10,地址是 0x10429f98。因为栈是从上往下使用栈空间,所以 inc 变量地址值比 count 变量地址值小(这只是实现细节)。简单来说,goroutine 把函数 main 栈帧中的 count 变量的值拷贝并传递给了函数 increment 栈帧中的 inc 变量。
increment 函数中将 inc 变量的值加 1 并打印:
inc++
println("inc:\tValue Of[", inc, "]\tAddr Of[", &inc, "]")
程序 1 中第 22 行代码输出应该是:
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
执行完 incr 变量自增后,栈空间变成图 3:
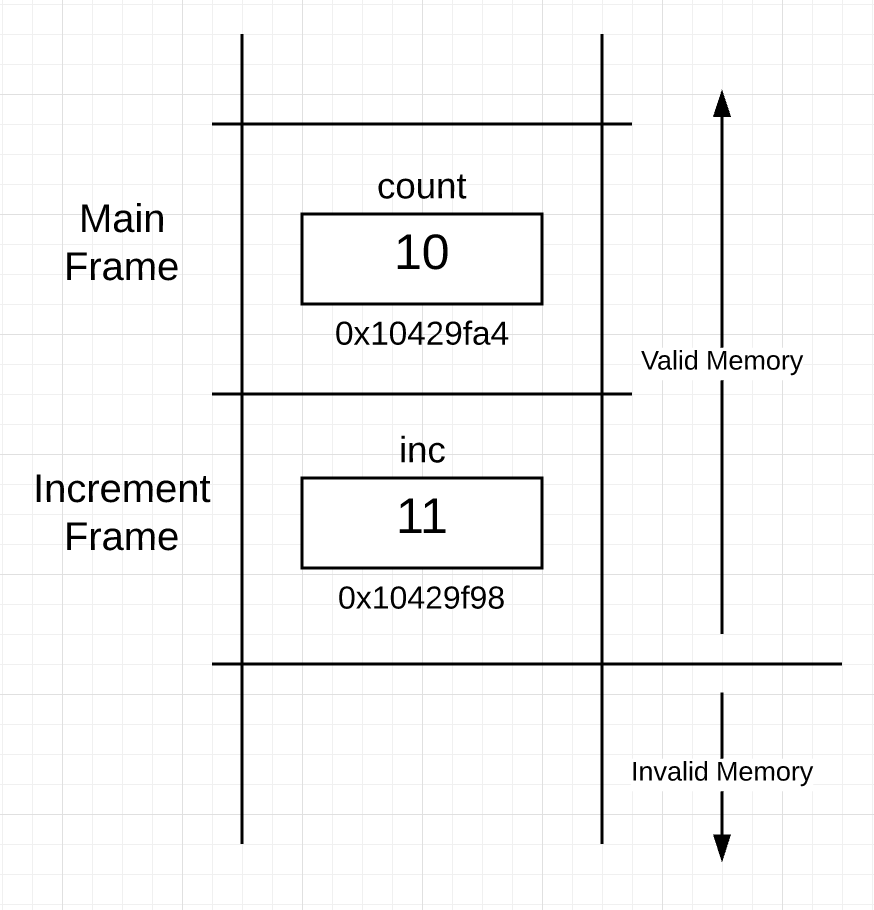 图3
图3
程序 1 执行完第 21 和 22 行代码之后,increment 函数返回,流程控制权又回到了 main 函数,main 函数执行第14行代码,打印 count 变量的值和地址。
println("count:\tValue Of[",count, "]\tAddr Of[", &count, "]")
程序1的完整的输出如下:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 11 ] Addr Of[ 0x10429f98 ]
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
main 函数栈帧中 count 变量的值在调用 increment 函数前后值没变。
函数返回
被调用的函数返回并将控制权交还给调用函数时栈空间发生了什么?简单的回答是,什么也没发生。图 4 是 increment 函数返回后的栈空间:
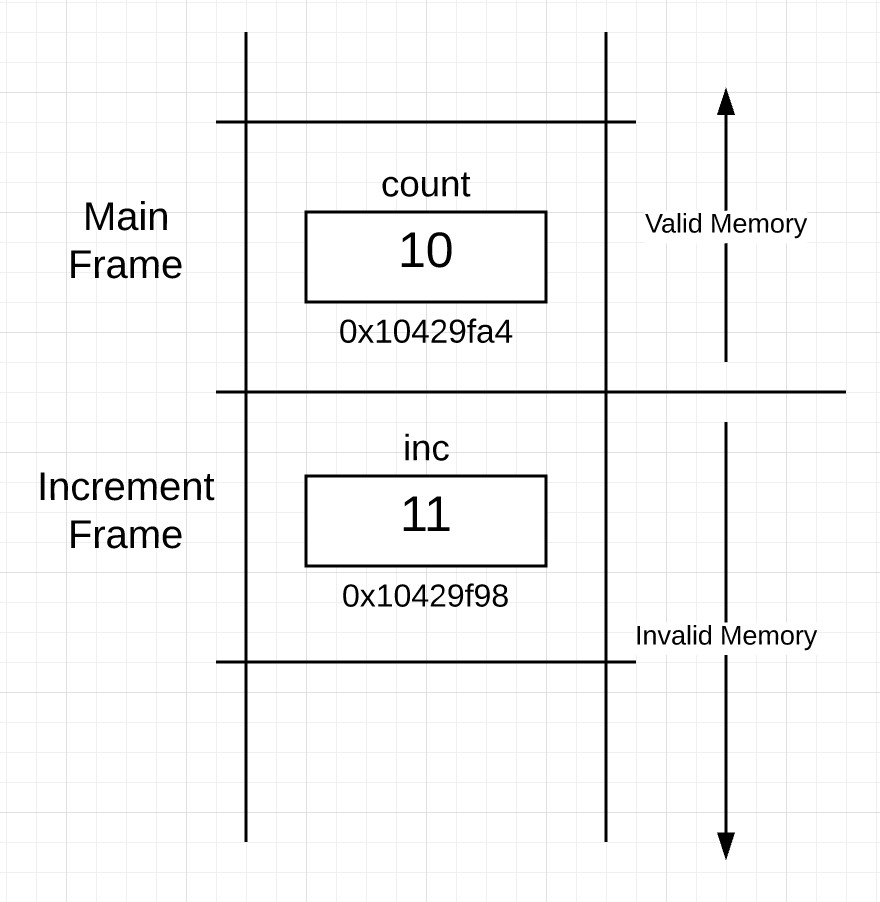 图4
图4
图 4 所示栈空间看起来和图3相似,只是 increment 栈空间现在变成了不可用内存,这是因为现在 main 函数栈帧是活跃的栈帧。函数返回之后,没有立即清理函数的栈空间,因为不确定是否还需要使用这块内存空间,只有再次有函数被调用并且使用到了这块内存空间时,才会去清理。
值的共享
如果想在 increment 函数直接操作 main 函数栈帧的 count 变量要怎么办?这时候就需要用到指针。指针可以和函数共享变量,让函数可以直接读写这个共享变量的值,即使共享变量不在自己的栈帧内。
如果不需要共享变量,那么就不需要使用指针,使用指针是为了共享,并且当阅读代码时,也应该把 & 操作符当做共享来看。
指针类型
任何类型(无论是自定义的类型还是内置类型)都有一个与之对应的指针类型,用来共享数据。比如内置类型 int 的指针类型是 *int,自定义的 User 类型的指针类型是 *User。
指针类型以 * 开头,并且所有指针类型用相同的内存大小(4 个字节或 8 个字节)来表示内存地址。在 32 为系统(比如 playground),指针类型大小是 4 个字节,在 64 位系统中,指针类型大小是 8 个字节。
规范的说, 指针类型被认为是字面类型(type literals),也就是说指针类型是通过已有类型组合而成的。
直接内存访问
程序 2 展示了以变量的地址作为参数来调用函数,在 main 函数栈和 increment 函数栈之间共享 count 变量
// 程序 2
package main
func main() {
// Declare variable of type int with a value of 10.
count := 10
// Display the "value of" and "address of" count.
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
// Pass the "address of" count.
increment(&count)
println("count:\tValue Of[", count, "]\t\tAddr Of[", &count, "]")
}
//go:noinline
func increment(inc *int) {
// Increment the "value of" count that the "pointer points to". (dereferencing)
*inc++
println("inc:\tValue Of[",
inc, "]\tAddr Of[", &inc, "]\tValue Points To[", *inc, "]")
}
在程序 2 的第 12 行,调用 increment 函数传递的参数是 count 变量的地址而不是 count 变量的副本,通过&操作符来获取了 count 变量的地址。这里依然是「按值传递(pass by value)」,不同的是,传递的是地址的值而不是int类型变量的值。
increment(&count)
在 increment 函数中,需要能接受 int 类型地址参数的形式参数,所以程序 2 的第 18 行函数参数类型声明为 *int:
func increment(inc *int) {
调用了 increment 函数之后,栈空间如图 5 所示:
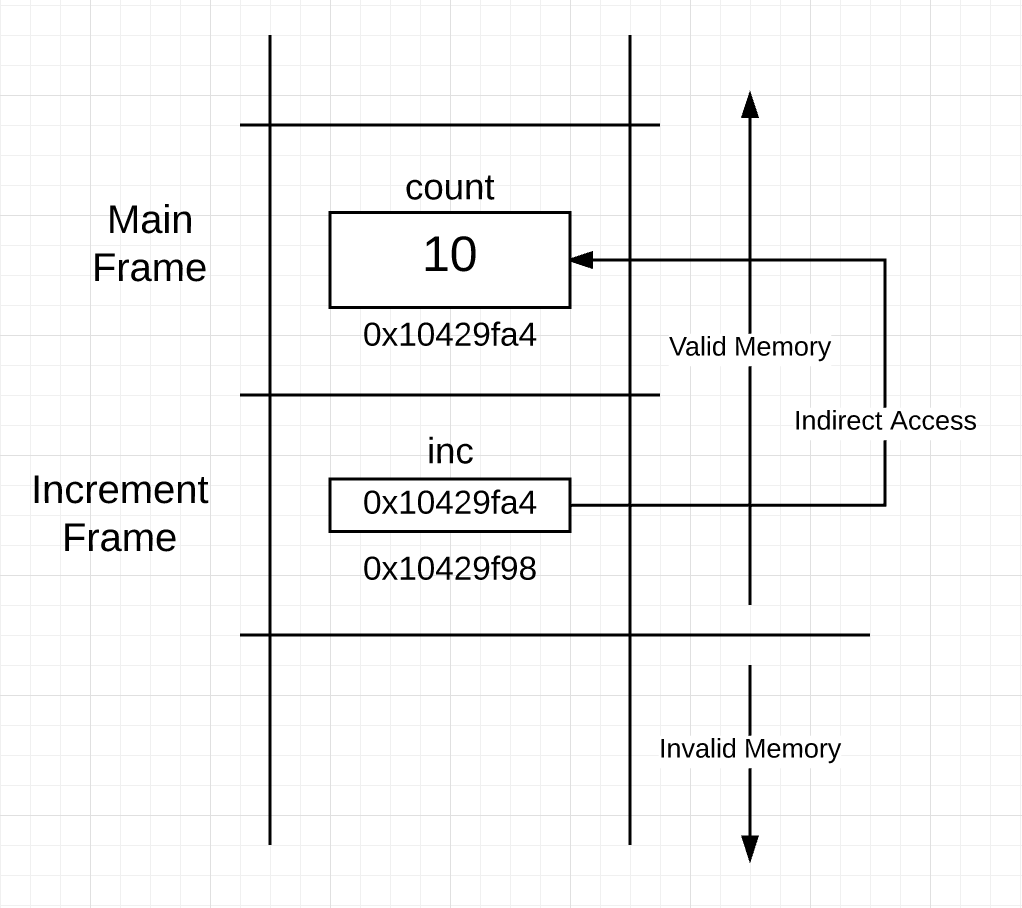 图 5
图 5
increment 函数栈空间中的 *int 类型的 inc 变量指向了 main 函数栈空间中的 count 变量。使用这个指针类型变量,increment 函数可以间接读写 main 函数空间的 count 变量。
在程序 2 的 21 行,* 符号和指针类型变量一起使用时,表示取指针变量指向的值的操作,在这里就是获取 main 函数中的 count 变量。指针类型变量允许在函数栈帧空间外间接读写指针变量指向的内存空间,我们把通过 * 符号间接访问内存空间的方式叫指针的解引用。
*inc++
当程序 2 执行到 21 行时,栈空间如图 6 所示:
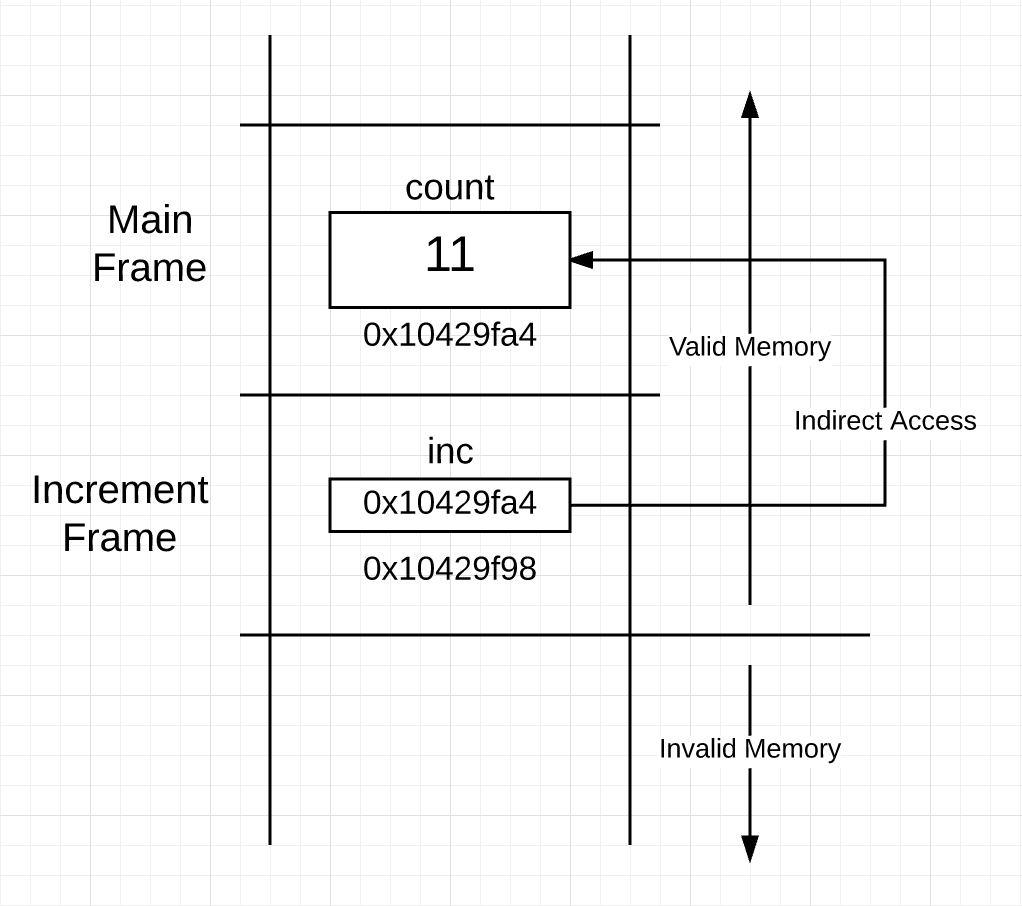 图 6
图 6
程序 2 的完整输出:
count: Value Of[ 10 ] Addr Of[ 0x10429fa4 ]
inc: Value Of[ 0x10429fa4 ] Addr Of[ 0x10429f98 ] Value Points To[ 11 ]
count: Value Of[ 11 ] Addr Of[ 0x10429fa4 ]
可以看到,inc 指针变量的值和 count 变量的地址值相同,通过指针类型可以间接的访问栈空间外的内存,increment 函数通过指针修改了 inc 指针变量指向的值(也就是 count 变量),当 main 函数重新获得控制权后,就可以读取到 count 变量的新值。
指针变量并不特别
指针变量和其他变量一样,并不特别,同样需要内存空间,同样存储这值。除了指针类型指向的类型和指针类型大小相同外,唯一让我们感到疑惑的是 * 字符,在函数 increment 中,* 表示操作符,表示指针解引用,而在函数声明中用来声明指针类型变量。如果可以愤青指针类型声明和指针解引用操作,应该就没那么困惑了。
总结
这篇文章描述了指针背后的目的以及 golang 中栈和指针机制的工作方式,这是理解 golang 语言机制、设计哲学的第一步,也有助于写出一致的、可读性好的代码。
从这篇文章我们学到了:
- 帧边界为每个函数提供了独立的内存空间,函数在自己的帧边界内执行
- 如果函数被调用,会存在两个栈空间的转换
- 值传递(by value)的好处是可读性高
- 栈空间很重要,栈为帧边界提供物理空间
- 在活跃栈帧以下的栈空间是不可用的,只有活跃栈帧和它以上的栈空间可用
- 函数调用意味着 goroutine 需要在栈空间上开辟一块新的栈帧
- 在函数调用时,如果被分配的栈用到了栈空间,相应的栈空间才会被初始化
- 指针是用来共享变量的,以便于函数可以间接访问自己栈帧外的变量
- 所有类型都可以通过其指针类型来共享
- 指针类型变量允许间接访问函数栈帧外的内存空间
- 指针变量和其他变量一样,并不特别,占用内存空间,并且存放值